

The dataset
First of all we needed to find a good data set, that contains text regarding different topics that are overlapping and not, texts that are short and long, and those that might be written in different styles, with and without slang. So we decided to scrape a popular Swedish forum called Flashback (https://www.flashback.org/). This is a quite old forum (> 10 years old), it is still active, so it should contain a decent amount of posts dedicated to a big range of topics.
The way we scraped it is as follows: the forum contains topics defined by the site (e.g. Home, Culture, Politics, etc). Every root topic might have multiple subtopics, and the final level is the thread, where people have discussion. We managed to scrape all the first posts for every thread, and assigned it to one of 16 root topics. We managed to obtain about 143K posts this way. This is a big data set, so we shrunk it by filtering out empty and too short (less than 100 words) posts. We assumed that the first post of the thread should be the most relevant and long enough, since the person who creates it describes the issue in a detailed way in order to start a decent discussion. Finally we took only ~24K posts to train and estimate the models.
The models
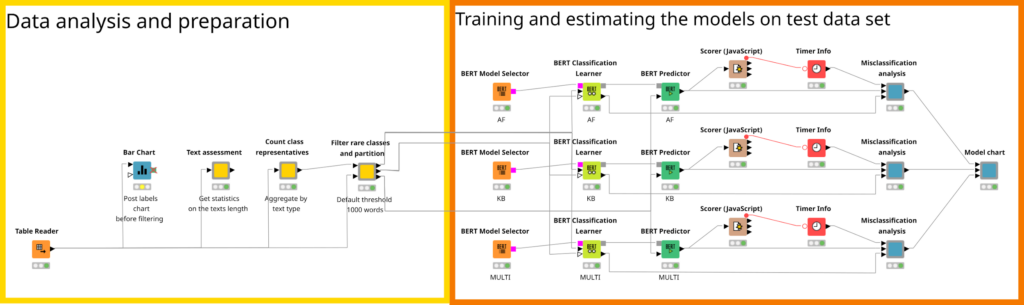
In the workflow we built we used 3 models:
Let’s refer to them as AF, KB and Multi consequently. All these models have the same architecture so we can conclude that it is correct to compare their predictions, while the training conditions are the same. The difference between them is the corpuses that were used to train them. Moreover the Multi model is a flexible model that was trained by Google on multiple languages corpuses, so it is not specified for Swedish.
The transfer learning concept
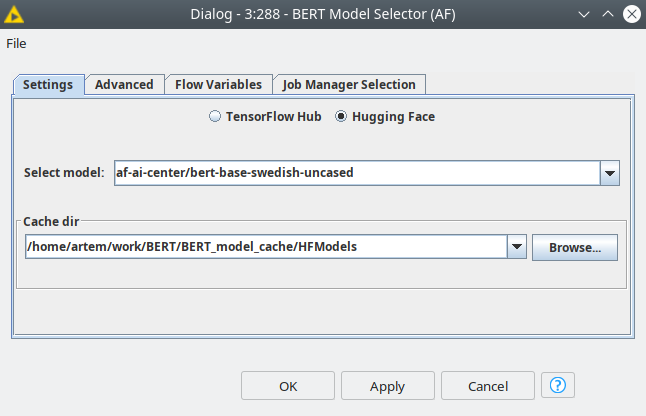
In order to get the model for text classification we used Bert Redfield extension for Knime. This extension is a codeless solution that allows to obtain state-of-the-art models for text classification. The main concept here is transfer learning — first the model should be trained on a large amount of data, then we just only build a more simple classifier on top of that model and fine-tune the combined model on a much smaller data set. In our case the BERT is the large model that was already pre-trained on big corpuses of texts, and the simple classification neural network is automatically generated by one of the nodes from extension. Then we fine-tune the model on the Flashback dataset we gathered in order to train a topic classifier. Fine tuning process is way more simple and cheaper rather than training the model from scratch and can be done with commodity hardware (GPU is preferable).
The training
To train and estimate a supervised model we should follow a standard procedure — split the data set into training and test. We are also going to have another data set for validation, this is extremely helpful in order to understand how many epochs are necessary to train a robust model.
| Mean | Median | Min | Max |
| 216.56 | 165.0 | 100 | 1000 |
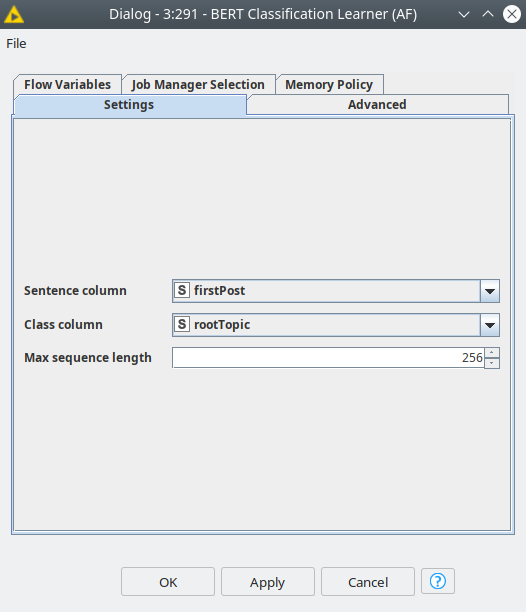
Once we have selected the models with BERT Model Selector nodes, we can have 3 separate branches for each of them, however the training, validation and test data will be the same. Once we feed the BERT model and data to BERT Classification Learner we can set up the training parameters. In order to compare the models we use the same parameters. The first one is a model parameter — maximum sequence length was set to 256 tokens. This value was selected because we calculated statistics of the words in the posts with Text assessment component. We got for mean and median 216 and 165 consequently. This way we can be sure that more than a half of the texts will be completely considered during the training, the longer texts however will be truncated.
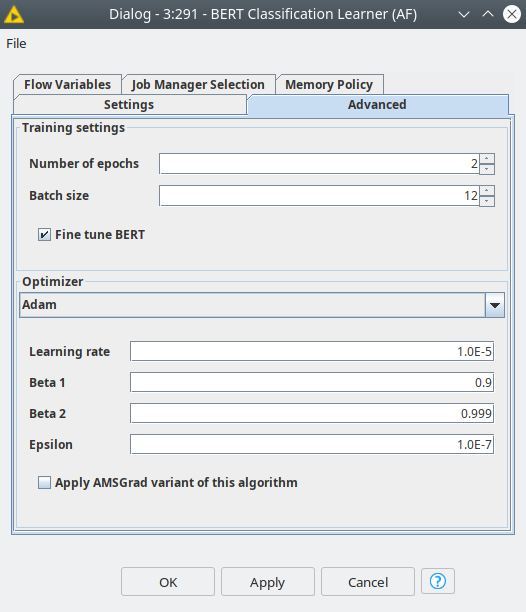
The next parameters are dedicated to the training process: number of epochs and batch size. Number of epochs defines how many times we are going to use the training data set for forward and back propagation procedures — shortly the training process itself. The idea of transfer learning implies that the model we are fine tuning already “contains” a lot of knowledge about the general domain, while we only need to tweak it a little. This way we trained for only 2 epochs, this can also guarantee that the model will not be overfitted.
The batch size parameter should be set up heuristically and it is dependent on the hardware used for training, mostly the available RAM or video RAM and the maximum sequence length. So please set this parameter according to your capabilities so you will not get OutOfMemory error, that notes that the texts that are turned into BERT embeddings do not fit into available memory. We used value 12 for this parameter, and we had 8 GB of video RAM.
One more parameter is a checkbox called “Fine tune BERT” controls whether the weight of the BERT will be trainable, or only a small on-top classifier will be trained based on the embeddings provided by the default model. If not active the training process will go much faster at the same time it may require to train for a bigger number of epochs and the model probably would be less accurate. So this is kind of a trade-off, but we would recommend to activate this option to get the best model and train for only 2-3 epochs.
The final set of settings are dedicated to the optimizer. Here you can pick any optimizer from Keras library and configure it. In our experiment we used Adam optimizer with learning rate = 1E-5, the rest values were default.
The model estimation
Once the models are trained we can easily apply them to the test set with BERT Predictor node. The pattern is the learner-predictor for any other supervised learning algorithm in Knime. We feed the trained model and the test set to a predictor. The component called Misclassification analysis we can select the columns with real and predicted labels, and also pick to the classes that will be shown in the dynamic confusion matrix.
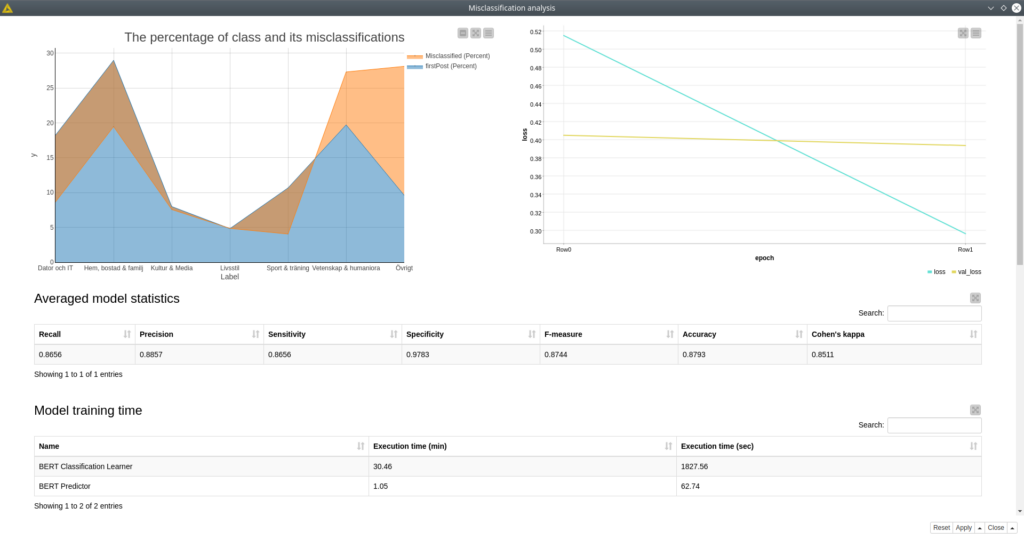
The component creates the dashboard that shows many model’s features. On the top left of the dashboard you can find the ratio of the class representatives (blue) and the ratio of the misclassifications for this particular class based on the overall number of classifications. On the right side there is a plot for training and validation losses, so this plot is helpful for defining the number of training epochs. The rule is quite simple here: you need to find the point where two lines start diverging, usually the training line (green) would always go down, while validation one (yellow) might go up, which means that the model becomes overfitted.
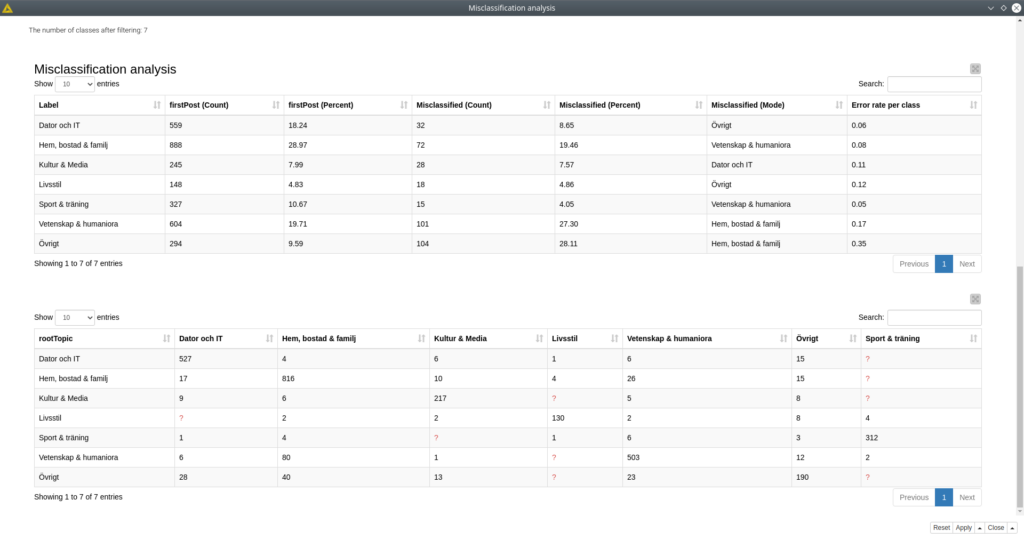
Then goes the table with the average model metrics for all classes followed by the table with the times spent on training and predicting. Finally there goes the tables with the misclassification for every category and a dynamic confusion matrix that can be configured in the component dialog.
Conclusion
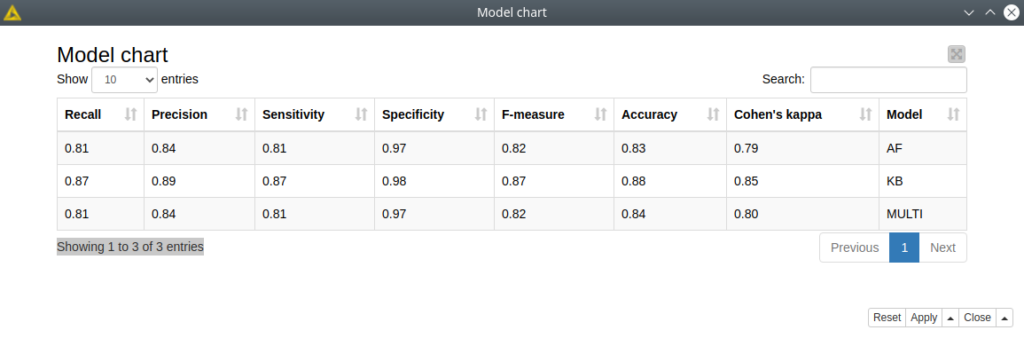
Figure 6. The overall model chart with the averaged model statistics. The best results are obtained with KB model.
As we trained 3 models we can conclude that the best one is the KB model with Acc: 88%, F1: 87% and Kappa: 85%. Which is quite a good result for a 7-class classifier. This we can explore in Model chart component, that gathers the statistics from all 3 models.
From the misclassification analysis we did we can see that some topics seem to be overlapping with the others, we can assume that the most unclear topics were “Science & Humanities” and “Other” that were mostly misclassified with “Home, accommodation and family” and vice versa. Moreover the topic “Other” had a lot of misclassification with the rest of the topics. This means that “Other” is an extremely broad topic, what actually comes from its name. Anyway it was a good example showing that BERT handles even such hard cases quite well.
A more thorough analysis might get some ideas how to improve the classifier, but it is out of the scope of this article. At the same time you can see that using BERT along with Knime is very easy and does not demand coding skills, only some basic knowledge of Knime and machine learning. Moreover the trained models can be easily saved in native Knime format and deployed to other workflows.
Installation
To use the BERT extension you need to install the KNIME TensorFlow2 extension so you need to use KNIME 4.2 version or newer. In “KNIME preferences” you can create a Deep Learning environment for Python. Next, you need to install additional packages for this environment. Here is the list of packages compatible with the nodes and their versions:
- bert==2.2.0
- bert-for-tf2==0.14.4
- Keras-Preprocessing==1.1.2
- numpy==1.19.1
- pandas==0.23.4
- pyarrow==0.11.1
- tensorboard==2.2.2
- tensorboard-plugin-wit==1.7.0
- tensorflow==2.2.0
- tensorflow-estimator==2.2.0
- tensorflow-hub==0.8.0
- tokenizers==0.7.0
- tqdm==4.48.0
- transformers==3.0.2