

In today’s data-driven world, the sheer volume of text data generated from various sources such as emails, social media posts, and online articles presents unique challenges and opportunities. One of the techniques that has emerged to navigate this complexity is topic modeling, a method that helps us discover the hidden thematic structure in large collections of texts. This introduction aims to demystify topic modeling, explaining its significance and basic functionality in a way that is accessible to non-technical individuals or analysts new to the field. The use of LLMs, requiring relatively minimal set-up, mirrors strategies adopted by companies like Redfield to effectively implement these techniques. In this guide, we’ll show how to detect tax fraud.
Table of Contents
What Is Topic Modeling?
Topic modeling is a technique that uses machine learning to automatically sort a large collection of documents into different themes or topics. For example, if you have thousands of news articles, topic modeling can quickly organize them into groups like politics, sports, or technology without the need to read each one individually. This method not only saves time but also helps in neatly arranging information, making it easier to see patterns and connections that might not be obvious at first glance.
The process involves the examination of words used in the texts and the frequencies with which they appear. By analyzing these patterns, topic modeling algorithms can group words and phrases that often occur together across different documents into ‘topics’. It’s crucial to note that a ‘topic’ in this context doesn’t necessarily correspond to our everyday understanding of the word but represents a cluster of terms that frequently co-occur, suggesting a common theme.
For instance, a collection of articles containing words like “ball”, “score”, “team”, and “tournament” frequently might be grouped under a sports-related topic whereas “fish”, “rod” and “line” would be grouped under a fishing-related topic. The beauty of topic modeling lies in its ability to perform this categorization automatically, allowing analysts to focus on interpreting the results rather than combing through the data manually.
Moreover, topic modeling is highly versatile and can be adapted to numerous applications, from detecting trends in customer feedback to identifying research gaps in academic literature. This technique not only enhances our understanding of large text collections but also informs decision-making across various sectors including marketing, security, research, and customer service.
As we delve deeper into the specifics of how topic modeling works and the different algorithms that power it, keep in mind the fundamental goal: to simplify the complex and bring structure to the unstructured. This understanding will guide us through the more technical aspects of the topic and how they are applied in practical scenarios using tools like Knime, a platform that facilitates these analyses without requiring extensive programming expertise. With this foundation, we are better equipped to appreciate the nuances of topic modeling algorithms and their applications in the real world.
What Is Text Classification: How Does It Fit Into Topic Modeling?
There is a temptation to mix the slurry of terms: topic modeling, topic extraction and text classification. The key difference is that topic modeling (or extraction) tends to describe methods where the topics are extracted from the text; this would be the case where the exact topics are not known in advance. Contrastingly, text classification is used to classify (or map) some text against a set of predefined labels. In this way, text classification is not strictly the same as topic modeling, however depending on the requirements of a project, this could also be a valid fit for similar use-cases.
To keep things simple, this article will partially overlap these terms, however it should be made clear that in a traditional sense, topic modeling and topic classification are strictly not the same.
This guide will give an overview of methods for topic extraction and conclude with a specific method for text classification which we use at Redfield.ai in order to help our clients detect fraud. It will also investigate the general concepts and methodology behind topic modeling in general including the most popular statistics-based topic detection methods, then an outline of deep learning methods (especially large language models). Hopefully you will be able to follow along!
What Is Topic Modeling Used For?
To start with a concrete example, say that the government would like to detect possible cases of tax fraud or evasion. One possible way of doing this is by extracting topics (which are known to be problematic) from tax statements and expenses. To do this, one would need to choose a selection of regular (non-suspicious) labels, along with some other labels that may indicate fraud. Some regular labels could include “interest” and “medical expenses” (costs which are regularly cross referenced), while some suspicious labels could be “charitable donations” or “miscellaneous”. In this case, the goal would be to classify the documents against each of different categories of these topics, in other words, to determine whether or not each expense fits any combination (or all) of these labels.
In the context of phishing and fraud detection, topic modeling helps identify suspicious patterns and commonalities in communications, such as emails or messages, which are indicative of fraudulent activities. By analyzing the topics that frequently appear in known phishing emails, such as requests for personal information or urgent financial transactions, organizations can develop more effective filters to screen and flag potential threats, thereby enhancing their security measures.
As an example, an auditing firm might want to classify some emails according to a set of usually discussed topics in order to detect possible ‘suspicious activity’, this is a part of fraud detection. Perhaps some topics in particular would correlate with spammy or fraudulent content, and this is a way of picking up on some fraudulent emails that might otherwise go unnoticed.
Beyond security applications, topic modeling is also widely used in several other areas. For instance, it is employed in customer service to analyze feedback or complaints, enabling companies to categorize issues and improve service delivery. In content management, publishers and media outlets use topic modeling to classify articles and recommend content to readers based on their interests. Additionally, in academic research, it is utilized to sift through large volumes of academic papers to identify prevailing research trends and gaps in the literature. These diverse applications demonstrate the broad utility of topic modeling in extracting meaningful insights from complex, unstructured data sets.
Additionally it can be used for content summarisation, search engine optimisation, customer feedback analysis, document clustering, trend analysis, personalisation, competitive analysis, and much, much more. Now it’s time to move on to discuss the technical background for the most common methods.
What Are The Different Methods For Topic Modeling?
Technical Overview
Firstly about statistical models/methods. In the context of topic modeling, these models, often referred to as topic models, view documents as mixtures of various topics to analyze and categorize content. Topics are extracted using only the words in texts themselves. There is no external data (or training data) introduced into the models (and in this sense it is better to have more data and longer documents to accurately extract the topics). As a consequence, we rely heavily on the text preprocessing, for example, using lemmatization to ensure that two different word forms are represented as the same word.
Among the variety of topic modeling methods, two primary methods which are often used are Latent Dirichlet Allocation (LDA) and Non-negative Matrix Factorization (NMF). These are Bayesian models that do not rely on deterministic outcomes but rather on the probabilistic distribution of topics within documents.
Unsupervised machine learning methods are generally used for topic modeling and topic classification. You can read a bit more about unsupervised models (often referred to as zero-shot learning models) here.
In most cases the model of choice will be a pre-trained language model. Pre-trained language models, (including BERT and GPT) can be used in a couple of different ways for topic extraction. We can use the standard text-completion functionality (like ChatGPT) to provide the model with some text, and simply ask it to extract the topics, also usually specified a structured output to simplify the parsing of the response afterwards. Alternatively we can extract the embeddings from the model in order to extract relevant information.
Statistical modeling
What is Latent Dirichlet Allocation (LDA)?
Latent Dirichlet Allocation (LDA) is a statistical model used in natural language processing for topic modeling. It analyzes a collection of documents, identifies patterns of frequently co-occurring words, and uses these patterns to determine the topics within the text corpus. Similar to latent semantic analysis, LDA uses a document term matrix to facilitate this analysis.
LDA views each document as a mixture of various topics. This model is useful because it can uncover hidden relationships between themes in texts, even if these relationships between latent topics are not explicitly mentioned. For instance, in a large set of documents, LDA determines the main topics discussed by identifying specific words that frequently appear together, thus grouping them into topics.
This process simplifies the management and analysis of large text collections by automatically outlining the main ideas or themes, allowing users to organize, summarize, and understand extensive data without prior knowledge of potential topics.
Moreover, LDA approaches text analysis probabilistically, not deterministically. This flexibility allows the model to account for the natural variability in language use across different documents, making it effective in handling the complexity of real-world text.
Here is a more detailed outline of the specific algorithm that underpins LDA. Two initial variables/inputs are selected: the number of topics and the corpus of documents. It is assumed that each document is generated from a mixture of these multiple topics together, each characterized by a distribution over words.
As a first step, LDA initially randomly assigns each word in the documents to a topic. This random assignment serves as a preliminary basis for the model to begin learning, from which the model will start to converge during training.
Through techniques like Gibbs sampling or variational inference, LDA continuously refines these assignments. It calculates two probabilities for each word:
- The likelihood of the topic given the document P(Topic | Document)
- The likelihood of the word given the topic P(Word | Topic)
These probabilities help update each word’s topic assignment in relation to inverse document frequency and to other words in the same document. After multiple iterations, the model reaches a point where the topic assignments do not change significantly, indicating that the topics are meaningfully distributed throughout the documents. It should be noted that due to this, there can be problems if there is truly an imbalance in the number of certain topics among the documents.
You can find an article on knime.com that shows some more details.
LDA facilitates topic modeling analysis by uncovering hidden relationships and themes in text data, enabling the analysis of vast amounts of text to extract relevant information in real-time and create breakthrough experiences.
What Is Non-negative Matrix Factorisation (NMF)?
NMF, or Non-negative Matrix Factorisation, is another effective method for topic modeling. Although only a brief overview will be provided here, as a true implementation can get quite complex, it’s beneficial for those interested in topic modeling to pursue further research.
NMF interprets the data as additive combinations of basis features (topics). Each document is represented as a linear combination of common topics, and each topic is a cluster of words that frequently co-occur across documents. This method, much like latent semantic analysis, uses a document term matrix to map out the relationships between terms and documents. Essentially, think of it like mixing different colors from a set palette to paint various scenes, where each color represents a different topic. The non-negativity constraint is crucial; it ensures that the features and their mixtures are additive, meaning that you cannot subtract a word from a topic or a topic from a document’s representation. This aligns intuitively with how topics are expressed in text: through the accumulation of similar words. This constraint simplifies the interpretation of topics, as it models the way natural language builds meaning—through addition rather than subtraction.
NMF simplifies complex text data into interpretable themes and their associations with documents, making it effective for uncovering latent structures and hidden patterns in text documents. The method’s strength lies in its ability to distill large volumes of text into meaningful thematic components, which is key to summarizing and organizing textual data. By breaking down vast texts into simpler thematic units, NMF helps in identifying underlying themes that might not be apparent at first glance, facilitating deeper insights into the content.
Large Language Models (Including LLMs)
In the last few years, there has been a tidal wave of progress in the space of language models, positioning them as advanced topic classification algorithm modeling tools. These unsupervised models, including topic classification and topic modeling APIs, open-source libraries, and SaaS APIs, learn patterns in human language from exposure to huge volumes of text, offering a comprehensive approach to organizing and summarizing topics at scale, understanding hidden topical patterns, and making data-driven decisions.
The reason to use an unsupervised model like GPT is that they can understand text extremely well. Relying on statistical methods (and the corresponding preprocessing techniques) is heavily limited by the scale of data (small amounts of data yields very poor results), and the statistical methods usually rely on implicit assumptions about the distribution of topics across all documents.
Contrastingly, pre-trained language models are capable of extracting the meaning of sentences. They have the ability to ‘understand’ words in context, what they mean semantically and the different grammatical forms that they can appear as. As a result, synonyms are handled exactly as we would expect them to be. This means that it is less necessary to perform text pre-processing, and additionally the extra grammatical information actually can help the model determine the meaning of a word, sentence or phrase.
This brings us to the specific methods. There are two main methods, the first of which uses something called ‘embeddings’, while the other utilizes the regular text completion mode (like ChatGPT).
Embeddings
For the first method, it is important to understand what an embedding is. In the context of language models, an embedding is a way to convert words, sentences, or even whole documents into a form (usually a list of numbers) that the computer can understand and work with. It could be thought of as translating human language into a numeric representation that captures the semantic meaning of the text.
Another key piece of information to understand is that since the embedding can capture the meaning of a text, we are able to compare the embeddings (corresponding to different input texts) with each other to discover if the meaning between the texts are similar. This allows the model to recognize that certain words, like “happy” and “joyful” are similar in meaning because their numerical representations are alike. Thus, embeddings help the model to see and measure how close or far apart the meanings of different texts are.
We can also extend the use of this to classify texts. It’s possible to compare the embedding of a piece of text with a few different labels, and see which label is ‘closest’ to the text in meaning. For example, if we compare the embedding of the sentence “There is a man that likes to go fishing” to the embeddings for the labels “business” and “recreation”, it is most likely that the embedding would be closest to “recreation” and further from “business”. This can be used to classify documents against labels, simply by inspecting how closely the meaning of a text matches each of the labels.
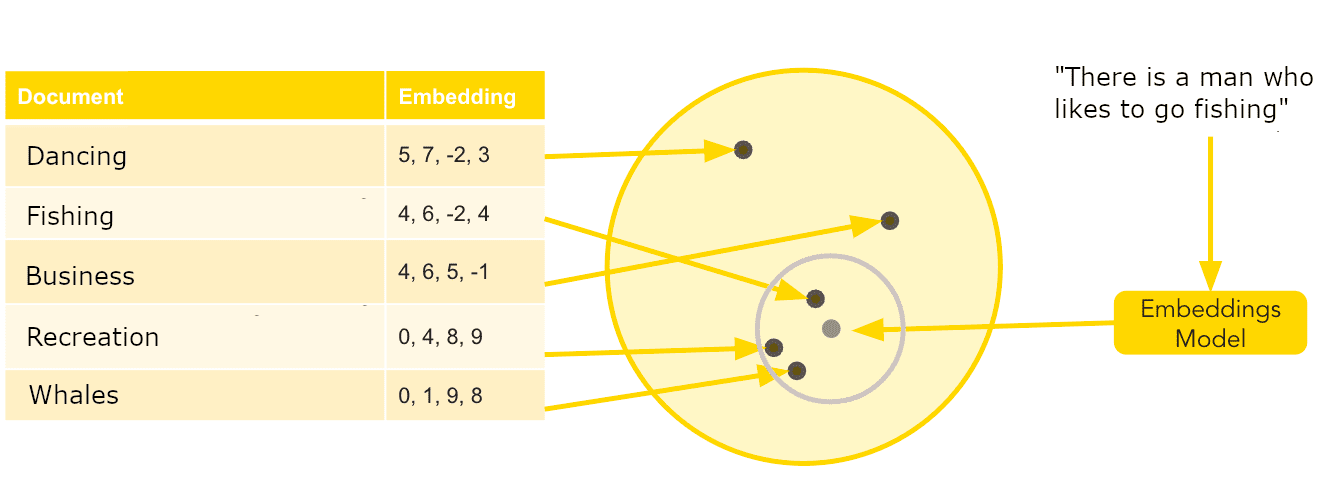
The above demonstrates this visually. You can see that the labels close to the provided text (within some arbitrary threshold) can be used as labels for that text. So without ever having trained a model, it is possible to classify them.
A final note: Again, strictly speaking this is topic classification and not topic modeling, however if you would like to perform topic modeling with embeddings (i.e. without predefined labels), I would suggest to read the following article which gives an outline into how it is possible to cluster texts together based on their semantic context, and thus perform topic modeling.
Text-Completions and Prompting
A Large Language Model (LLM), like ChatGPT, which needs to be provided with some instructions and data. Firstly a prompt needs to be created, where a prompt just refers to the text input that we provide the model. The prompt consists of raw text, but the following need to be provided as part of this prompt:
- The documents (the ones which are to be classified)
- The labels (the topics we want to classify against)
- Instructions of what to do (topic model)
- The format of the response (a structured parsable format like JSON)
In practice, a script would be written that can automatically go through some text documents, create the prompt (for that individual document), send it to the language model, receive the response, then parse the response and store the result somewhere. As a concrete example, the prompt template might be:
You are an expert at topic modeling.
Here is a list of the topics that we would like to classify an email against:
– marketing
– greeting
– phishing.
Here is an email that I want you to classify. Please evaluate if each of the above topics are relevant or not to the email below:
[START EMAIL] sender: john.dow@test.com; recipient: sally.moore@gmail.com; subject: “Test email”; text: “Hi, hope all is well, please let me know if you want to have a meeting soon. Regards, John”[END EMAIL]
Give me the response as valid JSON in the following format:
{“topics”: [topic_1, topic_2, …]}
… where topic_1 and topic_2 are one of the previously provided labels.
You may specify as many labels as you like, from zero or all of the labels. If you are unsure, please do not label the email as a topic.
JSON response:
Now, this prompt is provided to an LLM, which will (hopefully) give back an answer as the format that was specified.
Demo and tutorial
Following is an extended example and guide of how this can be done in Knime using Generative-AI: LLM prompting. This is a very detailed tutorial so it should cover everything specific to the specific workflow, but if you are unfamiliar with Knime, it is recommended to first follow an install guide and gain some familiarity with the tool before proceeding. You can follow the getting started guide.
Additionally, the OpenAI API will be used as our LLM, so I recommend signing up and getting and API Key (which is essentially a password) to access the service.
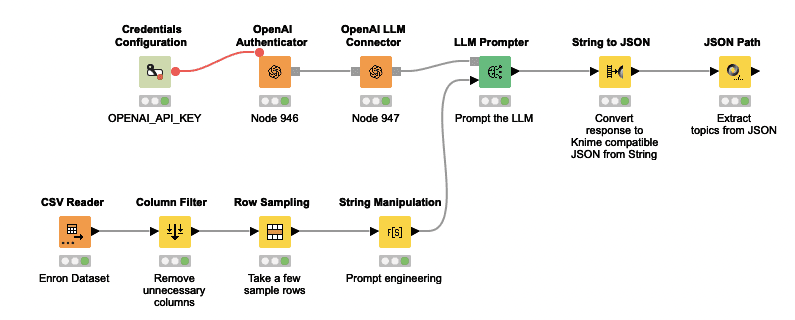
Here is the full workflow, in which we read in a CSV file containing some emails from the Enron dataset, prompt the model as described below and then extract the result.
You can find and download a sample of the dataset here.
It is sufficient to choose any one of the CSVs just as a sample set, any of them should work.
You can now drag in the CSV reader and specify the path to the CSV file that you downloaded. Note: check the box “Support short data rows”, due to the formatting of the file.
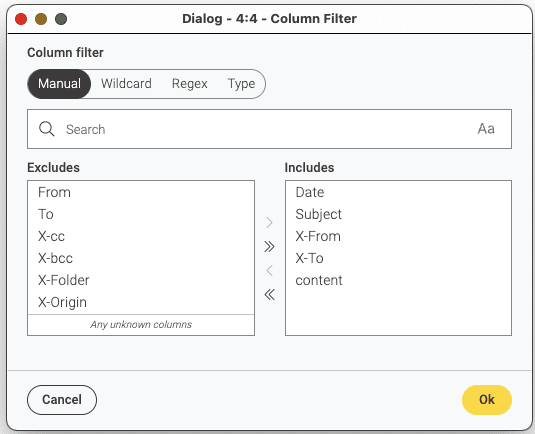
We can also use the Column Filter to remove all but the relevant columns (which you can see below), as well as the Row Sampling to take for example 10 rows (otherwise we will have a lot of data to process).
Now, we can perform prompt engineering, to make the input for the language model, exactly how it was explained earlier.
The String Manipulation node is used with the join() function, simply to concatenate all the parts of the prompt along with the specific information from the emails for each row. Note that each string just needs to be quoted properly, and double quotes need to be escaped with “\” (if within the prompt), and a new line character “\n” is added since we can’t include a new line implicitly in the formatting in the String Manipulation node.
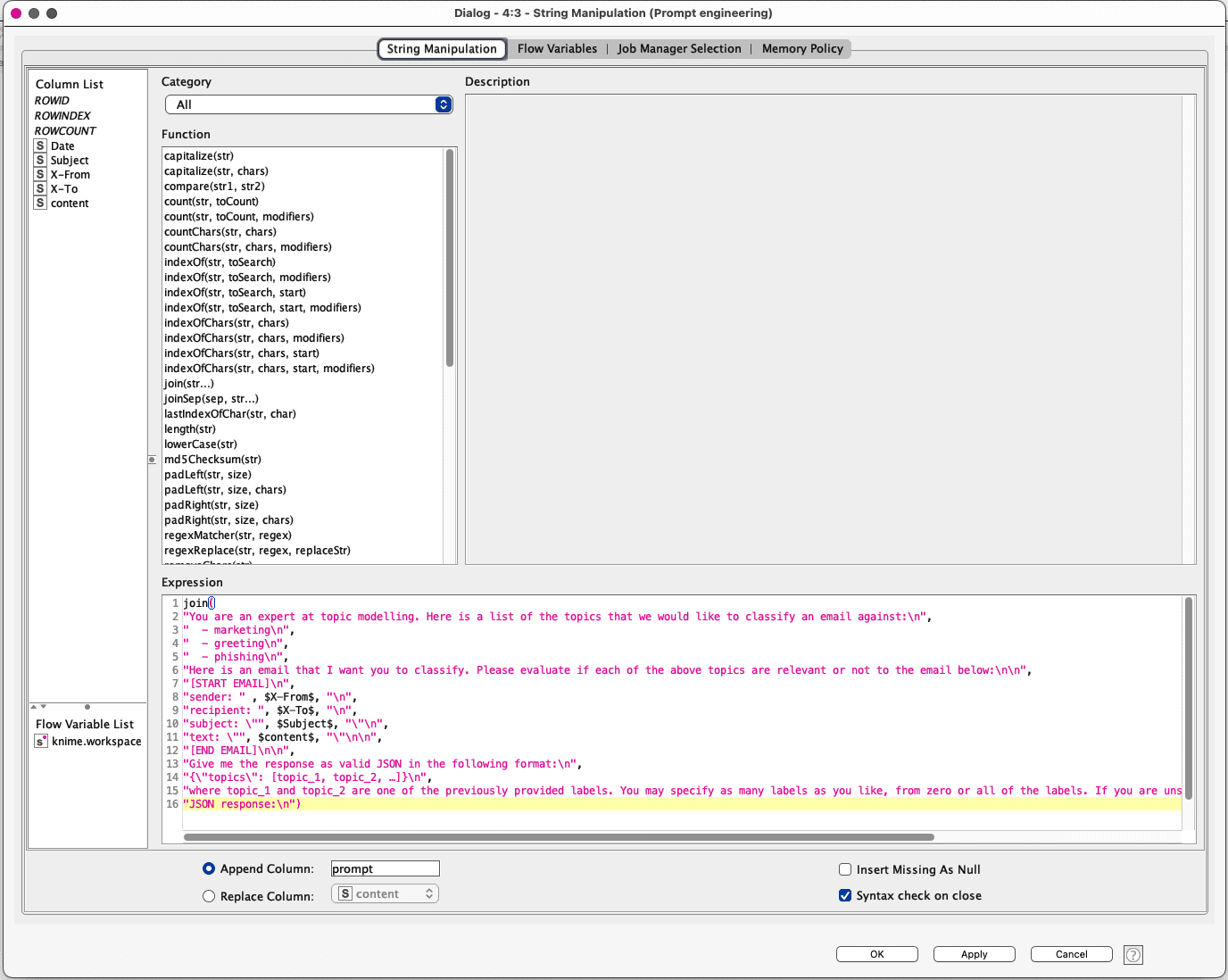
Also, you should name the output of this column ‘prompt’ (as shown above), but you can name it anything if you so choose.
Now we will shift to setting up the LLM. First we will have to prepare the language model prompter like in the screenshot below. You will need to provide the API Key in the Credentials Configuration node, and connect it to the OpenAI Authenticator, the OpenAI LLM Connector and finally the LLM Prompter.
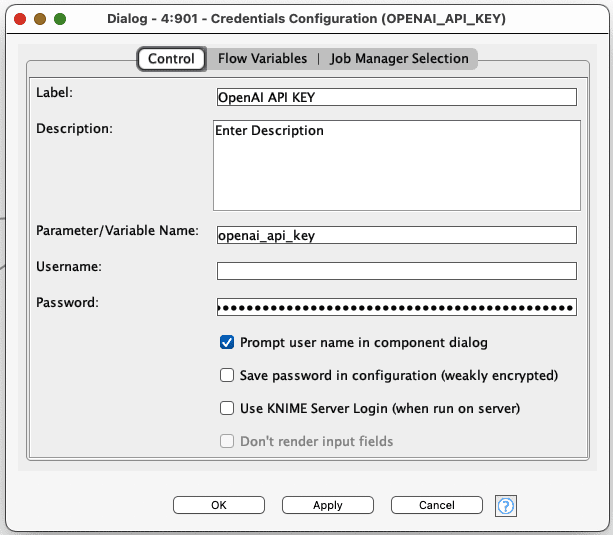
To provide the API Key, add it as the Password (as below) in the Credentials Configuration, and also name the parameter (in the Parameter/Variable Name field) whatever you like.
You will also need to open the OpenAI Authenticator and select the API Key which you just created/added.
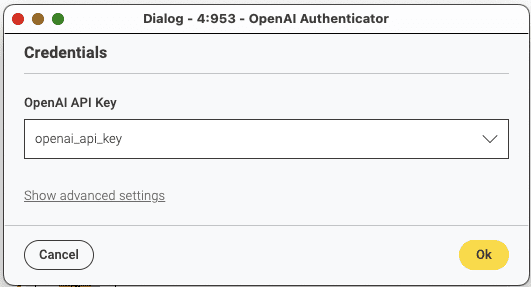
Now you can join the branches and prompt the model!
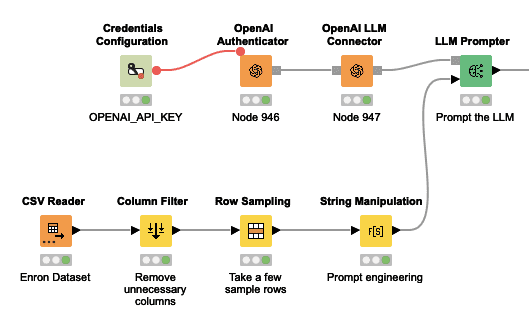
(Note that if you didn’t name the output column ‘prompt’ in the String Manipulation node, you will have to open the LLM prompter and specify which column to use as the prompt).
Now when it is executed, the response can be seen in the table in the ‘Response’ column.
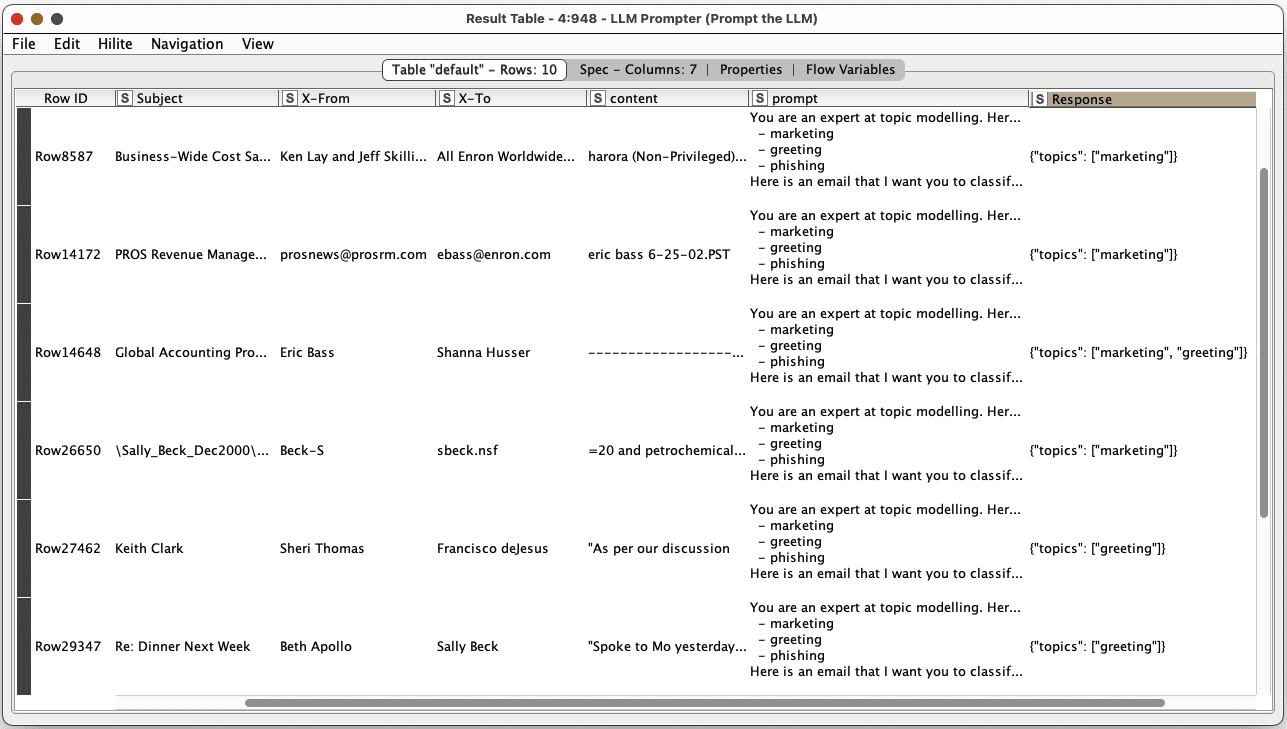
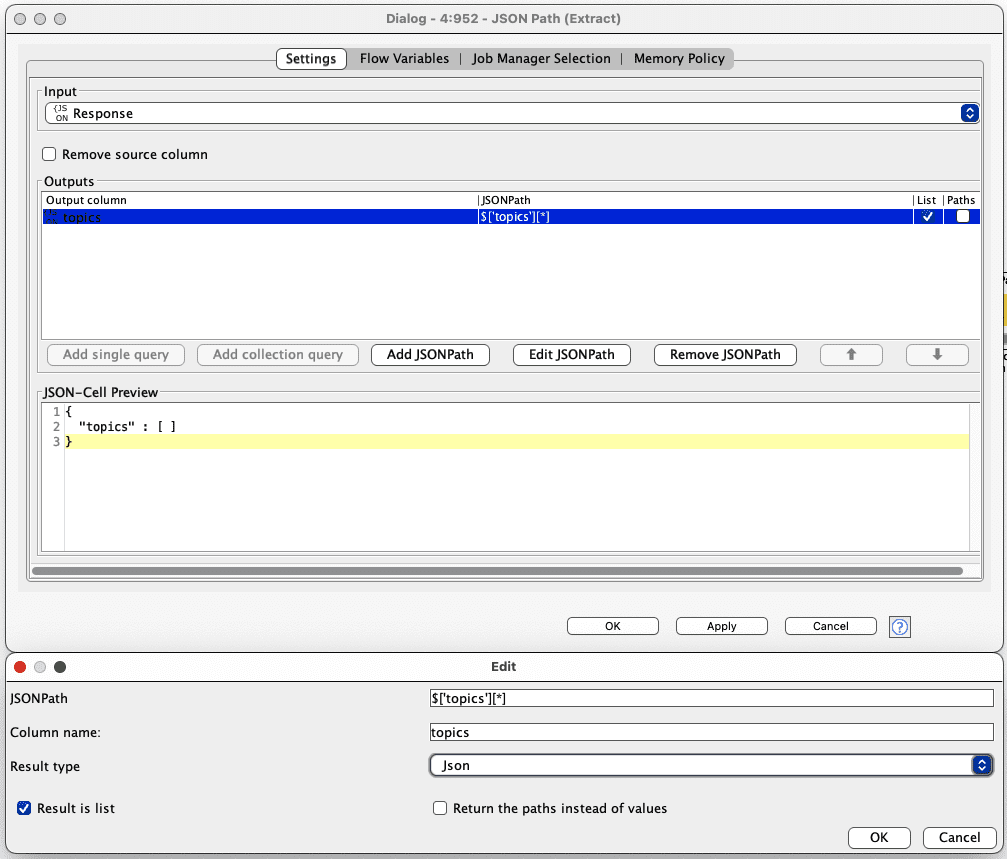
It is almost done! Now we will simply extract the topics into a list (or ‘collection’ as known in Knime). Use the String to JSON node, and in the node settings, select the ‘Response’ column.
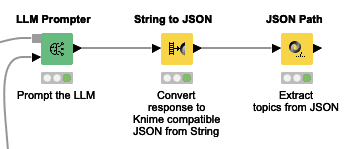
Now copy the settings as below by clicking ‘Add JSONPath’. Double click the row that appears under ‘Outputs’. The ‘Edit’ window will pop up (also as below), and fill in the settings as they appear here. Note to check the “Result is list” box to ensure the output is a list/collection.
Now, when you run the nodes, you will hopefully get something that looks like this, where you can see the topics column, showing which category each email was classified as.

So, by employing topic classification and modeling, it’s possible to automatically sift through almost any text and extract useful insights.
Congratulations! 🎉 You have made your first topic model classifier! If you have any more questions feel free to reach out to us at Redfield.ai.
More case studies: