

Table of Contents
Introduction
Contract review automation is the holy grail for contract management. Previous contract review technology hasn’t been good enough to displace the need for manual contract review…until now.
The goal of automating the contract review process is not to replace legal professionals, but to streamline the process, enabling attorneys to work more efficiently and minimising the fatigue of repetitive tasks.
Law firms, sales teams, financial institutions and even smaller business enterprises can benefit by allowing them to focus more resources on business decisions and strategy rather than minor contractual details that bear high risk.
In this article we’ll look at how contract review automation has been done, and investigate how recent developments in artificial intelligence (AI), machine learning (ML) and natural language processing (NLP) are now making it practical to automate document classification (provision extraction), named entity recognition (NER), risk detection, deviation detection and many more tasks.
Manual Contract Review
Before delving into the technology, we can start by looking at the manual review process .We can take the example of an attorney who is manually extracting provisions (or terms) from contracts one by one. It might be quick for an experienced attorney who has done this thousands of times, but it is potentially an expensive and unnecessary waste of their time.
Alternatively, a law firm may employ a junior to do the work at a reduced cost. Juniors will often use an instructional list to help them disambiguate provisions and clauses. The tradeoff for cheaper labour in this case leads to even slower work, which can be more prone to error (though their work is almost always reviewed by a mentor or attorney).
Semi-automated Contract Review
There are a number of computer based techniques which we can classify as ‘semi-automated’. The problem is that computers (without artificial intelligence) see text as nothing but strings of individual words and letters, attaching no semantic meaning to them.
There are two methods that have been used in the past. The first method is manually constructing rules, which match keywords, phrases or patterns to classify documents (provision extraction), or for extracting information (such as names or named entities). We can broadly call these ‘rule based’ methods. The second method uses comparison between documents as a proxy for classifying them. We can call these ‘similarity’ methods.
We’ll look at these in a bit more detail, showing what they perform well at, before moving to talking a bit more about the capabilities of artificial intelligence.
Rule Based Classification
Keyword Matching
A simple technique for building a provision extractor (classifier) is by matching keywords (or phrases) in contracts. If we can find a specific set of keywords that map to each provision, then we can classify new contracts by using these keywords. For example, a classifier looking for car insurance liabilities could look for the words ’car’, ‘auto’ and ‘liability’.

Regular Expressions
A more sophisticated version of keyword matching uses ‘regular expressions’. Regular expressions can also be used for keyword matching, but they enable more flexibility; they enable the programmer to more easily specify optional or alternative words and variations on phrases.
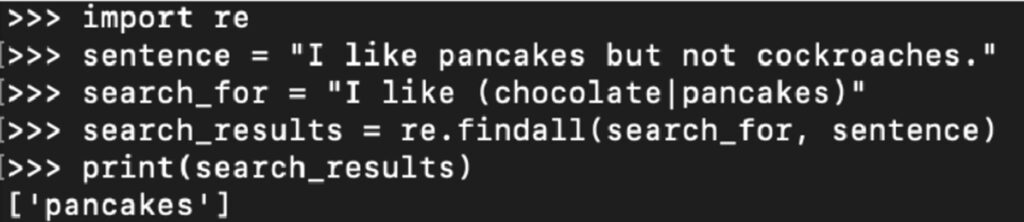
Additionally, regular expressions can also be used to extract specific information (especially named entities) by looking for specific patterns. If we also wish to automatically extract the name from the example phrase:
“The holder of the insurance John Smith is liable to…”
We could specify a pattern like:
The holder of the insurance [extract_name] is liable to
This would extract the text between “The holder of the insurance” and “is liable to”, to obtain the entity name:
extract_name = “John Smith”
This type of information extraction is called Named Entity Recognition (NER).
Document Similarity
The second technique for classifying provisions is by comparing provisions or documents. To be able to classify a new provision, we compare them with a collection of other provisions which have previously been annotated and labelled. We say that if a new provision has a high similarity to another provision, then they are likely to be the same provision.
We can illustrate this with an example. Let’s say that in our database we have two documents, each is labelled with a different provision. One of them is labelled ‘indemnification’ and the other ‘limitation of liability’. Now, let’s say that we wish to classify a new document. We don’t know if it is ‘indemnification’ or ‘limitation of liability’ (we restrict the example for the sake of simplicity).
We can then compute the similarity between the new document and each of the documents in the database. If the similarity between the new document and the ‘indemnification’ document is 87%, while the similarity with the ‘limitation of liability’ document is 45%, the classifier will determine that the new provision is ‘indemnification’. In a real-world case there would be many documents in the database covering many different clauses and provisions, results would be collated and averaged to obtain a more reliable result.
There are a variety of algorithms (from Diff to TF-IDF) for determining document similarity which we won’t get into detail, but can be worth a look at overview of text similarity if it whets the appetite.
Summary Of Semi-Automated Techniques
If we intend to manage a limited set of well-known contracts, then the rule based techniques can work quite well, however if we wish to work with previously unseen contracts, then we’re in for a problem.
It is possible to build more complicated manually programmed rules, but at some point this reaches a limit. There will always be documents for which you don’t have rules telling the system how to parse a document. As a consequence limited transparency in knowing what the system may or may not have missed.
The document similarity methods are more robust to variation, but often require a large set of annotated data, and it can only be used reliably for classification, not data extraction.
Is Machine Learning Really Necessary?
Before exploring the landscape of modern technologies, we’ll motivate why we might wish to use AI instead of other methods. We’ll get a bit technical here, but you won’t get lost by skipping to the next section.
Precision and recall are metrics that data scientists use to describe the performance of classifiers (for example, in provision detection). These metrics work on a per-class (per-category) basis. Precision is the proportion of true positives to all the detected positives:
precision = true_positives/(true_positives + false_positives)
Recall is the proportion of true positives to all the ‘real’ positives:
recall = true_positives/(true_positives + false_negatives)
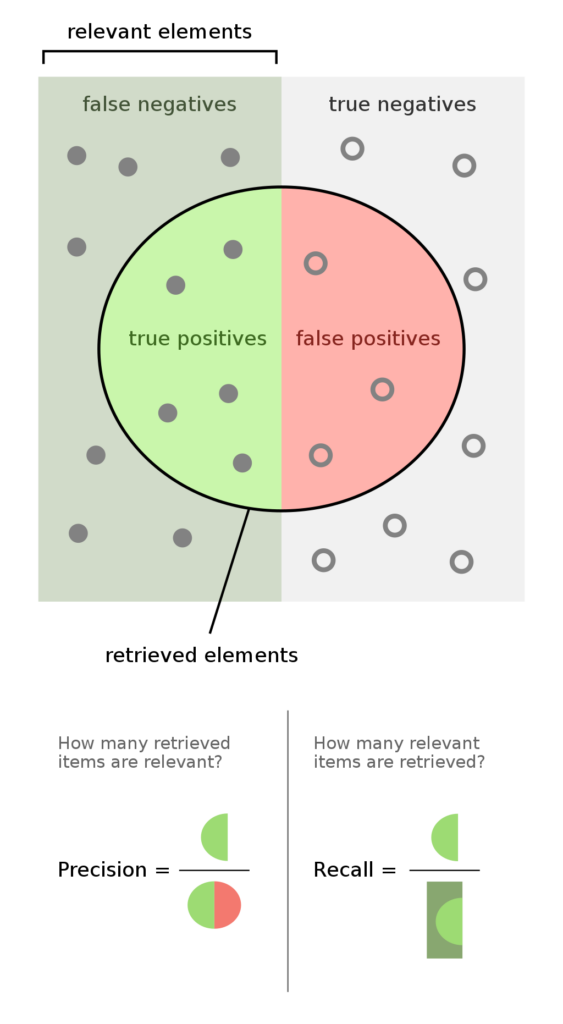
You can read a bit more about the definitions of Precision and Recall if you would like more technical detail.
As a specific example, let’s say that we have a set of 10 documents, 5 of which are labelled ‘indemnification’, and 5 are ‘limitation of liability’. Now, we get a model to ‘guess’ if each document is ‘indemnification’ or not. If the classifier guessed that 2 of the documents were ‘indemnification’, and both actually indemnification, we have:
precision = true_positives/(true_positives + false_positives) = 2/(2+0) = 100%
So our model was 100% precise on this class, despite the fact that it missed more than half of the actual ‘indemnification’ documents. Precision is useful for determining if the model avoids misclassifying items, but it doesn’t say much about if there were missed items. Alternately for recall:
recall = true_positives/(true_positives + false_negatives) = 2/(2+3) = 40%
Recall represents how many items should have been classified as ‘indemnification’ but were missed.
When working with classifiers in contract review automation, it’s incredibly important to not miss items, as this could carry significant risk. Conversely if misclassified items are accidentally included, they can easily be identified and manually removed. Thus, it is more important for a system to have high recall, rather than high precision.
In traditional automated contract review software, achieving high precision is feasible while achieving high recall is only feasible with extensive annotations and significant manual labour. With modern AI techniques we can minimise risk by tuning our models to achieve an appropriate balance between precision and recall with much less manual work. Contract automation can therefore be done extremely efficiently with minimal risk.
Artificial Intelligence Contract Review
The ‘semi-automated’ technologies can be useful, but they are also quite limited given their uncertain reliability, and how much manual work goes into developing the software. Machine learning on the other hand can provide performance approaching human-level accuracy at superhuman speed with less need for manual work.
Classification and Entity Recognition
Machine learning models perform exceptionally well compared to the previously mentioned semi-automated counterparts and they are much more versatile. While semi-automated models require precisely programmed patterns, machine learning models learn patterns in data all on their own, though they sometimes require annotated datasets.
For example, if we build a provision extraction model, we can show the model some examples of contracts, as well as their provision classifications. Once the computer has seen enough examples, it can learn the correlation between the contracts and their associated provisions. Now, once we have trained the system on enough documents, we can use this model to classify new documents.

Such a model can also be adapted to perform named entity recognition (NER), deviation detection, error detection and a variety of other tasks, providing that we have an appropriate dataset for each specific task.

Now, it seems that we haven’t yet escaped the need for labelling or annotations, after all, manual labour is one of the main things we are trying to avoid. The difference is that a relatively small amount of annotations are actually required. We can take advantage of other preexisting models, and build on top of them.
Language Learning From Unstructured Data
Developments in the field of natural language processing have seen significant growth in the last few years due to so-called “large language models”, such as BERT and GPT-3. These models perform well after learning from huge amounts of unstructured and unlabelled data. They are built on the ‘transformer’ architecture which learns patterns and relationships within context.
BERT alone is trained on a corpus of 3 300 million words! These models are able to learn the general semantics, structure and patterns of human language from many sources without any manual labelling or annotation (by humans).

We can also ‘fine-tune’ these models for a specific domain. For example, we can take the BERT model which has already ‘seen’ (been trained on) 3 300 million words, and then ‘show’ (train) BERT on text from contracts and legal documents. BERT would then learn the vocabulary, structure and meaning of language in the legal domain.
Transfer Learning
In summary, we can train a model like BERT on unstructured, unlabelled text data. It will learn the semantics, patterns and contextual information. We can then apply this model (as part of another model) for a more specific task, such as provision extraction.
The intuition here is that when we train the first model (BERT) on a mass of unstructured data, learning how to ‘understand’ language and linguistic patterns in general. Then, when we build a task-specific model (provision detection), we only need to train the model to understand specifically what provisions are. It should already have a good idea of what the English language looks like.
In a way, this process is similar to how humans learn the contract review process. A human will obviously learn to review contracts after learning how to read and write. Sentiment analysis using product review data provides an example of a similar type of model that our company Redfield AI has worked with.
Optical Character Recognition (OCR)
Digital contracts often contain digital text, but they are just as likely to be scanned versions of paper documents (thus, they are images). In that case, we need to use software to extract the text. It’s important to use reliable OCR software and the scans themselves are of high quality. If there are major transcription errors it is very unlikely that contract review software will be reliable without manual corrections. By contrast, artificial intelligence can be really robust against transcription errors.

Additionally, a contract review model can be integrated with OCR to provide a classifier additional spatial information about the original document’s layout. If we use only the textual information, then it may not be clear to the system where one section ends, and another begins, but with spatial information it is often easier for a system to interpret spacing, tables, signatures etc.
Contract Lifecycle Management (CLM) Software Integration
It is common to draft, edit and negotiate contracts using contract lifecycle management (CLM) software, especially in the more tech-savvy law firms. Such software assists in:
- Keeping track of renewal and expiration dates
- Collating data of individuals, companies or other entities
- Generating contracts from standard contracts or templates
- Search tools
- Contract collaboration
- Contract review management
- Tracking changes
If we use contract review software enhanced by machine learning, we can smoothly integrate the contract review process into contract management software. This can increase workflow efficiency by reducing the need for manual data management and input. Using artificial intelligence we can build models which enable:
- Enhanced search tools
- Generating contracts from similar contracts
- Detect contradictions
- Detect risks
- Automatically raise possible deviations
- Reliably extract entities
A Wrap Up on Contract Review Automation
Contract review automation and contract management software has existed for some time, but only recently been able to compete reliably with human levels of quality. Feel free to contact us or leave a comment if you have any questions; both general and technology related alike.
FAQs
What is automated contract review?
Automated contract review refers to the use of computers to speed up and improve the quality of the contract reviewing process, saving law firms and businesses time and money. Using computers it’s possible to streamline the process by automatically generating summary charts, extracting named entities, extracting provisions, detecting inconsistencies and more.
How does contract automation work?
Using machine learning and natural language processing tools, it is possible to build software that can learn how to extract information from contracts. Using a combination of general knowledge from a model such as BERT, with a specialised contract extraction model we can build software that automatically extracts provisions, named entities, inconsistencies and more.