

If you were told that a lynx is a medium-sized cat with large pointy ears and small tufts of hair under its cheeks, then you would probably be able to identify an image of one, even if you hadn’t seen one before…but can computers do this?
The terms ‘zero shot classification’ and ‘zero shot learning’ refer to a collection of related techniques and concepts (used in machine learning) in which anterior or auxiliary information is used at test time to predict classes which weren’t seen during training.
In a standard classification setup for example, all the classes that will be observed in testing (and beyond) must be present in the training set, however zero shot classification techniques can allow the prediction of unknown classes, even if they weren’t in the training set.
Zero shot classification can be used in a variety of domains. It had its beginnings in the field of computer vision (especially image classification) but has more recently been adapted to language-related applications including natural language processing (NLP) and even multimodal models.
How does Zero-Shot classification work?
There are a few ways in which we can perform zero shot classification, depending on the domain. At a high level, all techniques follow the same general conceptual procedure. As a first step we encode the input information using one network with some pre-training objective, and then compare this representation with some auxiliary information (or train a classifier on a new downstream task) to produce a prediction. For example, we could train a convolutional neural network (CNN) on an image labeling task, and then use that model as a backbone for a new image classification model.
Image classification with machine learning
We’ll look at the example of how image classification might work both with and without zero shot classification before getting into more general details. Let’s say that we are building an image classifier that takes images of cats and lynxes and automatically labels each image as either of ‘cat’ or ‘lynx’:
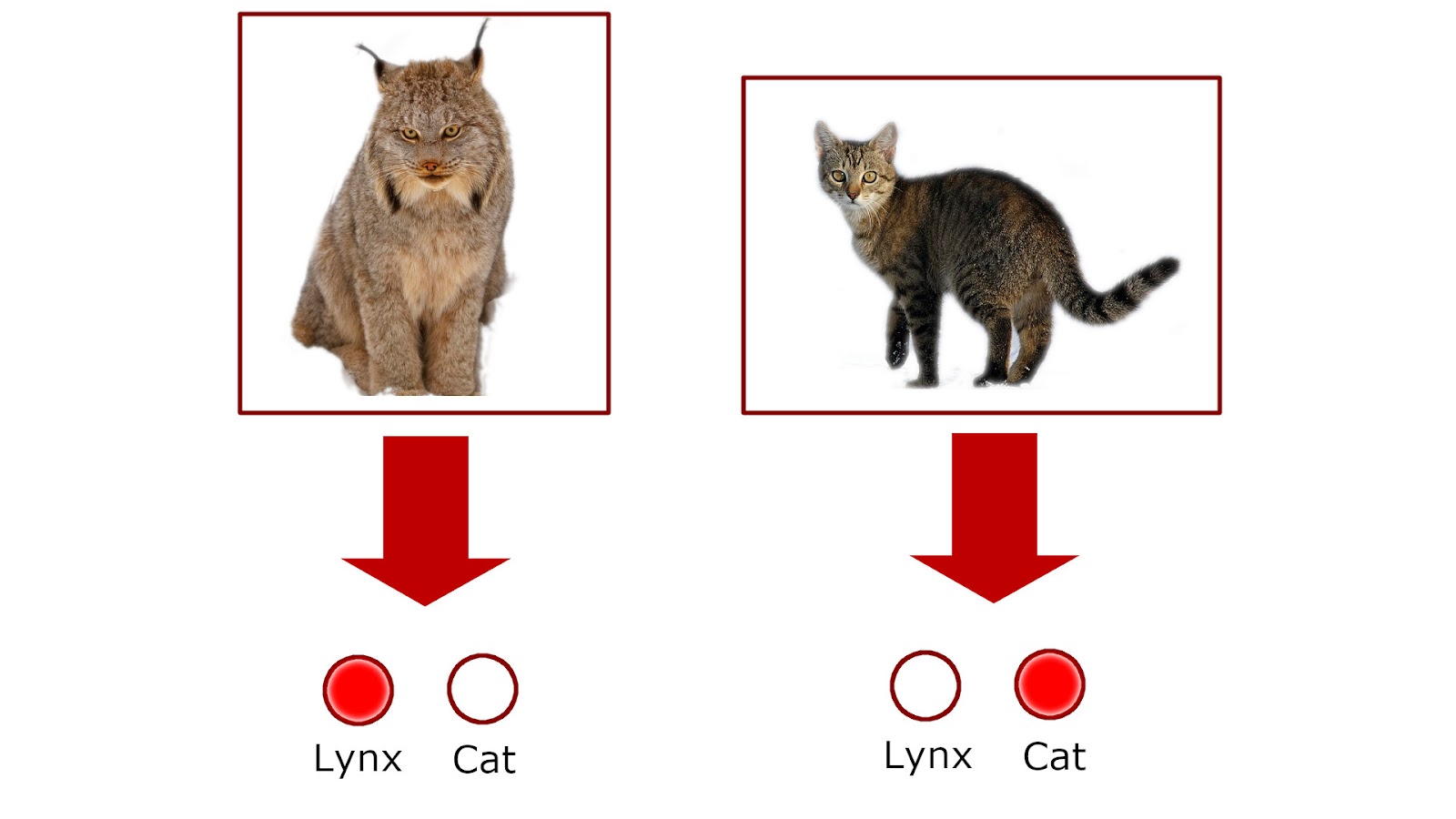
To build such a machine learning model, we would need to first collect a set of labeled images of both house cats and lynxes and train a classifier model on them. The hope is that the model would learn what visual features (shapes, colors etc.) correspond with each (class) label.

After the training stage, the model should be able to estimate if new, unseen images contain either a cat or a lynx. That is, it should be able to classify unseen images in the test set, according to the previously seen or observed classes.
Convolutional neural networks (CNN) are commonly used as the first processing step in such a model. CNNs are used as they are able to learn patterns in images. You can read more about the technical side in CNN classification. If you’re not particularly familiar with these machine learning terms, don’t worry, you can skip to the next section. The primary takeaway is that the model learns how to map the patterns in images to a set of labels (animals in this case).
In general, the classifier model consists of two main parts. Firstly the CNN extracts visual features (shapes, colors etc.), and transforms them into a set of feature vectors. These ‘feature vectors’, are just an abstraction of the visual features; they provide a mapping between the actual image and a numerical representation that the model can actually use to help predict the label of the image. We then run the (visual) feature vectors through a fully connected layer (and softmax function), which learns how to map the features to each label.
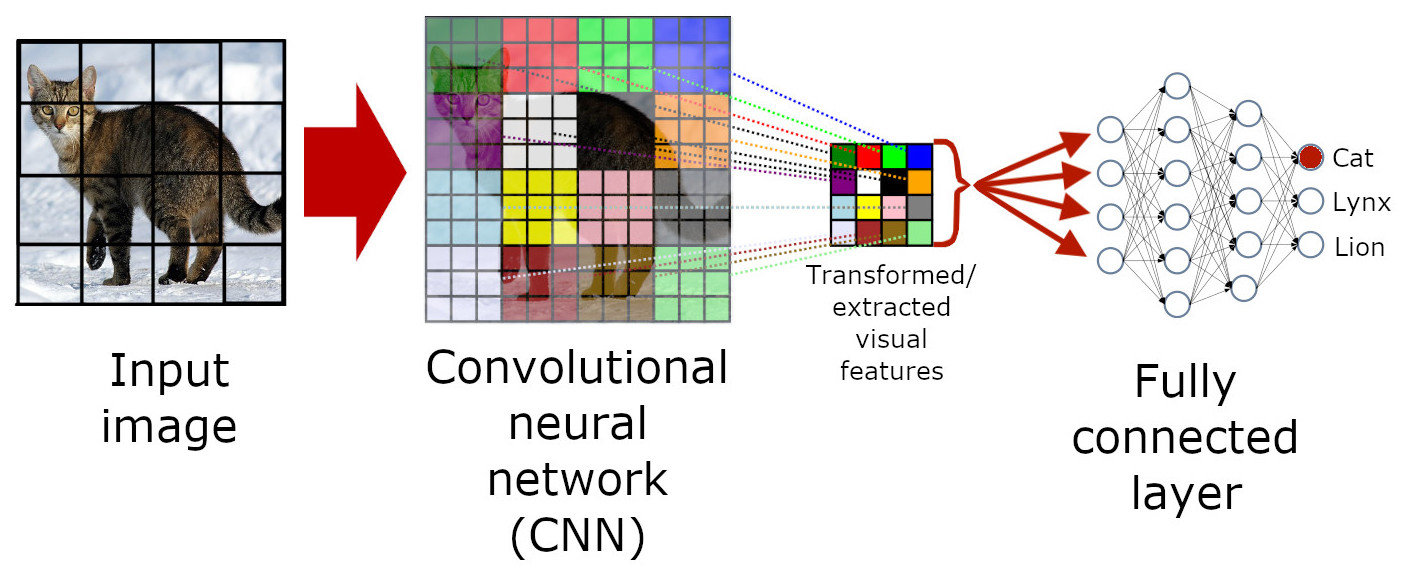
In reality, we get a score for each class (label/animal) that is the probability an image belongs to each class. The sum of these scores is 1 (sum of all possible outcomes is 100%). If we run an image of a cat through our model we might get the scores for the labels:
Lynx: 0.2 (20%)
Cat: 0.8 (80%)
We take the highest score ‘cat’ as the prediction.
Zero shot image classification
Now, what if we also wanted the model to be able to classify lions as well? The most obvious strategy would be to train the model on images of cats, lynxes and lions. This however necessitates annotating more images, and this task only grows as we add more classes. What if we wanted to classify cheetahs, leopards and other cat species as well?
Since this type of classifier only learns to classify each class label (animal) from the visual features, it becomes difficult to extend an existing model unless we train it on every new class. Alternatively, we could use zero shot classification, which would allow us to reuse a previously trained model, however for this to work we need to change the structure of our model. Using a model that predicts the class directly can’t be easily adapted for other tasks.
Instead of training a classifier to predict the class label directly (cat or lynx), we could train it to predict the attributes of these animals, and then use these attributes to predict the final class. Thus instead of labeling the images by the name of the animal, we could label (or annotate) their attributes. As per the cat example, instead of predicting ‘lynx’ or ‘cat’, we could instead predict the labels ‘pointy ears’ and ‘mane’ as an intermediate step, and then classify ‘lynx’ or ‘cat’ from these labels:
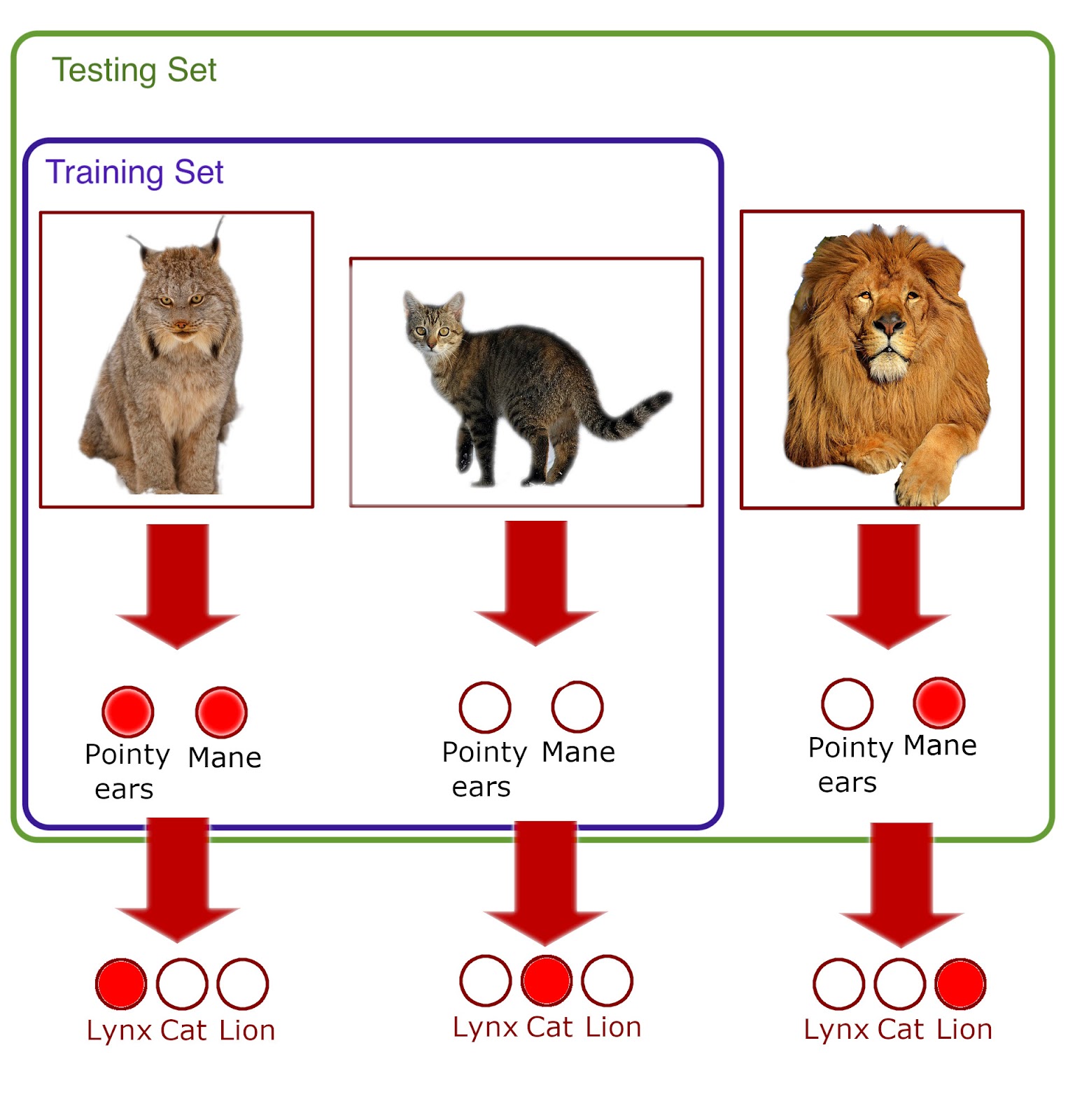
Note that more than one attribute label can be true for any image passed through the model, while for the animal label class, only one can be true, and this is by design. Additionally, this is a simplified example which wouldn’t work in practice due to the limited number of species, and the limited number of semantic attributes.
A good model should be able to learn the categories ‘pointy ears’ and ‘mane’ independently across many different species of cats. If both ‘pointy ears’ and ‘mane’ are both true (simultaneously) only when looking at images of lynxes, then the model will not learn to differentiate between ‘pointy ears’ and ‘mane’. In this case, as far as the model is concerned, there is no distinction between ‘pointy ears’ and ‘mane’ as they always exist in the same contexts.
Ideally we would train the model on a variety of species with a multitude of attributes. So, how do we arrive at a particular set of attributes? The choice of attributes are largely arbitrary. Attributes are often determined by the datasets themselves, for example the publicly available datasets ImageNet or Cifar-10.
We could also generate additional attributes by using data from other sources. If we know which animal is in an image, for example a lion, we should be able to get some of these attribute labels from encyclopedias, dictionaries, internet etc.
How do we get from attributes to class labels? The simplest method would be to manually generate rules, but this is a time consuming process that largely negates the need for zero shot classification. We could attempt to automate this process. Instead of matching the predicted attributes with a set of manual rules, can we create these ‘rules’ automatically from text?
Statistical Language Models
Why waste time creating rules when there is a wealth of text in books and on the internet that we can reuse? We could instead attempt to generate a class label for each image by matching the attribute labels to existing text. To classify a new image, we could compare the frequency that the attribute labels appear in various documents (for example entries in an encyclopedia), and we take the title of the document with the highest overlap (of attribute labels) as the class label.
If we extended the cat predicting model with more attributes, we could see that for a particular image, the model could output the attributes ‘mane’, ‘large’, ‘hunt’, ‘paws’, ‘tail’ and ‘orange’. In this case, we could check how often these attributes (words) appear in each entry in an encyclopedia. After checking through all the documents, we might hope that these words in combination are most frequent in the ‘Lion’ entry of the encyclopedia.
There are a variety of statistical models of this form that are even more advanced. TF-IDF is a good example of a model that compensates for an imbalance in frequency of words, and n-gram models can offer even better performance.
Unfortunately these statistical models do not provide state of the art performance in practice, and there are many variables to consider. We can again look at using zero shot classification, which is not only useful in the image processing domain, but also in the language (and text) domain. Instead, we can look at the field of natural language processing for a solution.
Language Model Classifiers
The field of Natural Language Processing (NLP) has recently attracted significant attention due to the development of models such as Bert and GPT-3. These ‘large language models’ perform well on a variety of tasks because they learn from tremendous amounts of unstructured and unlabelled data. BERT alone is trained on a corpus of 3 300 million words! These models are built on the ‘transformer’ architecture, and learn the general semantics, structure and patterns of human language from many sources without manual labeling or annotation.
We could even build our cat classifier in combination with BERT, which would enable us to make predictions of classes not in the training set. BERT encodes all words using latent embeddings; these are vectors consisting of 768 dimensions. If we modify our classifier model, we can train a model that projects the visual features into the language embedding space. This language embedding space is often referred to as a ‘semantic space’ as it encodes the meaning of words in a high-dimensional vector space.
If we reduce BERTs embeddings from 768 dimensional to 2 dimensional embeddings, the embedding space might look like the following. Let’s say that we pass 100 images through the model, and plot the embedding vector associated with each image. In our current example, each point in the space (embedding space) represents the class label of an image (which is just a word, as far as the model is concerned).
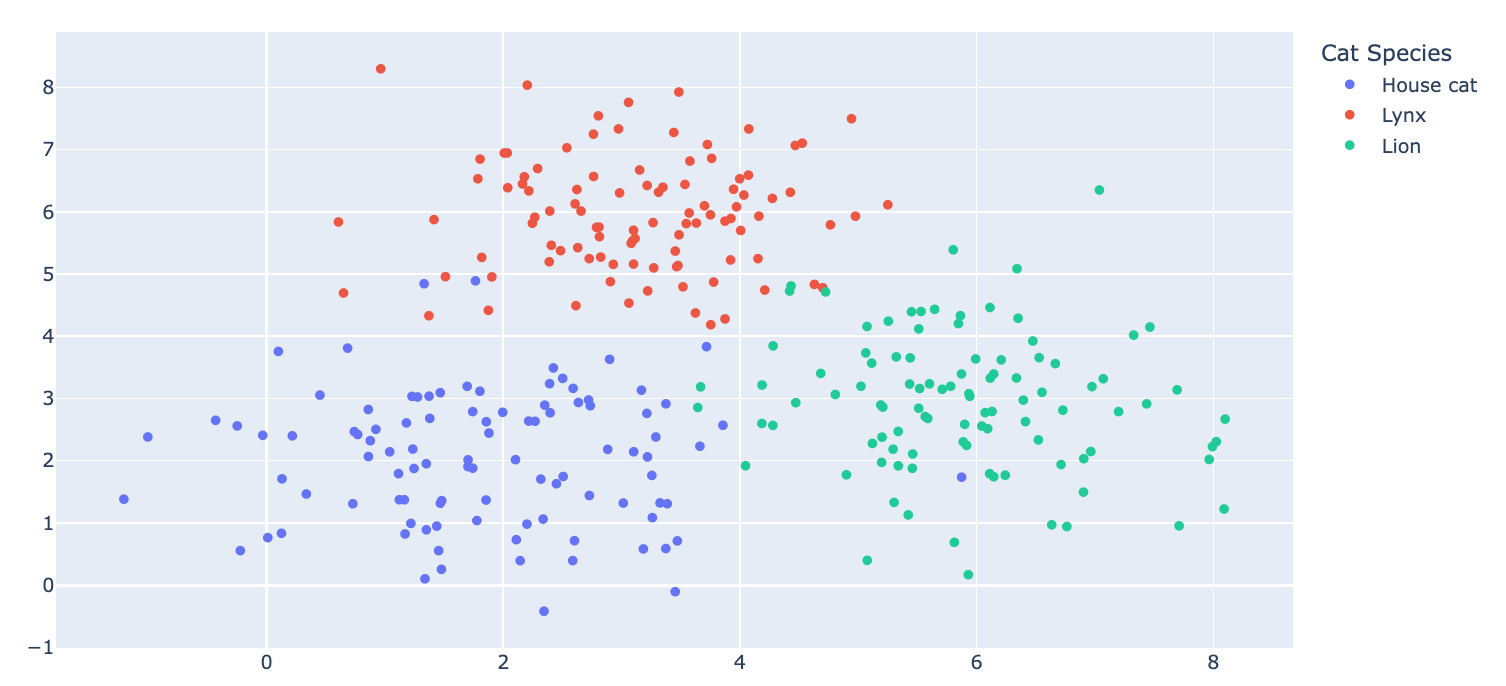
In this example, we can see that all the images of ‘lion’ cluster together quite well, and the same for all the other classes. We can train a model on only cats and lynxes, and lions would still hopefully cluster in the ‘lion’ part of the space, enabling us to classify them, even without having seen a lion before.
Zero Shot Language Models
The primary idea behind the paradigm of zero shot classification with language is to first pre-train a language model (such as BERT) using massive amounts of unlabeled data, enabling the model to learn and recognise patterns in language. We then take this model and fine-tune the model’s parameters using labeled data from the downstream task (target task, for example classification).
BERTs so called ‘general knowledge’ allows the model to generalise well across different language related tasks. In our previous example, we discussed ways we could improve the image classification model using BERT, however there isn’t anything stopping us from using BERT on language-only applications.
BERT is often used for language-only applications, especially text classification. An example of this would be topic classification, in which a model could scan documents (articles, contracts etc.) and label them based on their topic. There are a multitude of tasks that BERT can be used for in the language processing domain. Even automating contract review. [LINK]
Natural Language Inference (NLI)
A specific example of zero shot text classification is natural language inference (NLI). NLI is a popular language processing task in which we wish to develop a model to evaluate whether or not two statements are correlated with each other.
Specifically, we have a statement called the ‘premise’, and a ‘hypothesis’ which is a claim about that prior premise. It is the job of the model to determine whether or not the hypothesis agrees with the truth of the premise. The model will produce the labels ‘entailed’, ‘contradictory’ or ‘neutral’.
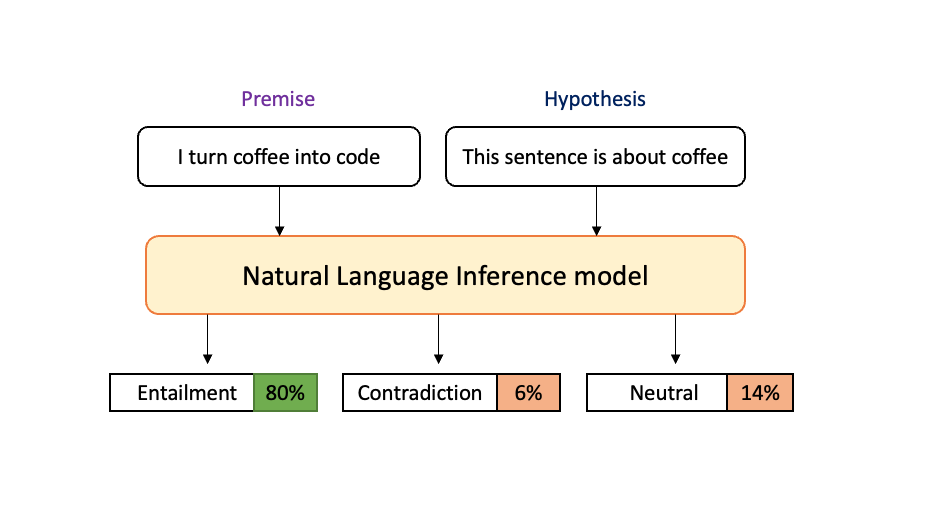
This NLI model is built on top of BERT, and is trained to map the relationship between premise and hypothesis. This allows us to perform text classification, easily, with no further training required. As such it is a very generalized zero shot learning technique, as we can classify data without training examples.
General Text Classification
We can apply such an NLI model for classifying any piece of text. In practice, we choose a sequence of arbitrary labels that we wish to classify our text against. For example, we might wish to classify an article against the labels ‘fish’, ‘cats’ or ‘dogs’. In this example, the premise would be the text in the article, and the hypotheses would be each label. We would test each label against the premise (article), and obtain a score for each about how entailed, contradicted or neutral each label is with respect to the article.
Here at Redfield we have developed a zero shot text classification (ZSTC) node for use in Knime. This makes it incredibly easy to connect a bert model selector node to the ZSTC node to classify text against any labels, even without a training phase.
Conclusion
In general, zero shot classification is the use of a machine learning model to perform classification over a set of labels it was not trained on. We have seen that the concept had its inception in computer vision models, but has been extended to language models, as well as multimodal models, and is excellent at classifying unseen classifier labels.